Will Bring-Your-Own-Agent be the new Bring-Your-Own-Key?
AI landscape right now seems to be moving towards agents than raw models. New model launches are still exciting, but what most people who are using AI through commercial tools or integrations these days are either interacting with some form of harness (an application layer on top of a model) or an agentic harness, which are primarily built around paradigms such as multi-turn tool calling chains, tools/MCP servers, skills, memory, sessions, etc.
Long gone are the days of simply copy/pasting ChatGPT outputs. Most of the excitement is now around the actual tools powered internally by AI models. And one of the fastest growing sector in this ecosystem is the Agent Harnesses. You've probably heard of developer focused ones like Claude Code, Cline, Kiro, etc, and there's Hermes that aims to bring value to non-developers.
Today, I was getting quite frustrated that my local agent setup is not portable. I have my local agent set up to behave specifically the way I want it to behave, configured with all the skills and tools I need it to have, but I can't run that same setup on my browser as a side-panel extension. For instance, I have a custom skill integrated with Tavily MCP so that my agent is able to conservatively invoke web searches and crawling, and generate search queries that produces results with just the right level of credit usage. But there just is no Chrome extensions out there that can integrate with this setup, and when I asked 5 different chrome extensions to look up some information, all of them ironically told me "I don't have the capability to perform web searches", which is infuriating considering they are literally running on my browser.
Same thing when I run an AI coding plugin on my IDE. Sure I can download Cline or Kilo Code, but again, it's not the same configuration as my CLI agent.
While I'm not a fan of it, Hermes does take a step in the right direction - it essentially is a self-hosted agent that piggybacks off of Discord/Slack etc as a makeshift reverse-tunnel, achieving some level of "access your agent anywhere" drawback that the current landscape has.
And that's kind of what I wanted to rant about today.
Agent Portability Problem
Many AI tooling these days provide a BYOK model, where you can use your own provider, or even your own self-hosted AI models, to be utilized within an agentic harness. However, BYOK is more of a monetary decision than "personalization". As AI usage evolves to become more personal, people have started to spend a great amount of time putting together their own set of tools, prompts, agent behavior, steering docs, etc, synonymous to how people have different preferences of IDEs and coding workspaces. Not being able to easily bring their agent across workspaces, let alone no easy way to replicate it, IMO is a problem that's slowly but surely creeping up.
There are roughly 3 core standardized components that make the agentic landscape possible:
- Native tool calling (models trained to produce and output standardized tool calling JSON)
- OpenAI-compatible endpoint schema
- MCP servers
Native tool calling is what allows any modern model trained with tool calling capabilities in mind to be slotted into any agent harness and work correctly. It's a training-time property in which the model has learned to emit structured JSON that signals intent to invoke a tool, rather than narrating what it would do in prose. This is what makes models interchangeable at the harness layer. As long as the model speaks the tool call format, the harness doesn't care which model it's talking to.
The OpenAI-compatible endpoint schema is the wire protocol that carries those tool calls across the network. It standardizes how a harness describes available tools to a model, how the model signals a tool invocation in its response, and how the harness returns a tool result back into the conversation. Because this schema has been so widely adopted by providers, local inference servers, and proxy layers, it functions as the interoperability contract between harnesses and model backends. A harness built against the OpenAI spec can switch providers, self-hosted models, or inference backends without breaking the tool calling integration.
MCP (note that the P stands for "protocol") standardizes what a tool does and how it's implemented, the final abstraction that decouples tool capability from the harness itself. A filesystem tool, a GitHub integration, or a browser controller implemented as an MCP server can be consumed by any MCP-compatible harness, regardless of which model or provider sits behind it. This is what makes tools portable in the same way that models are portable: the integration is written once and works everywhere that speaks the protocol.
Together, these three components form a loose but functional stack. But notice that these interchangeable and portable components are the building blocks of an AI agent, but there is no standardized protocol or schema that makes an AI agent itself actually portable.
Logistical Gaps
I strongly believe that there is a very compelling case and portable agents are inevitable. It's just the matter of who does it first.
There's definitely some reasons why commercial entities would be against it tho:
- Vendors benefit from lock-in at the harness layer. As seen by Claude Code, Cursor, Copilot etc, the selling point is increasingly the agent, not the model.
- No standard agent serialization format. There's no equivalent of a Dockerfile for agents - ie an agent manifest that said "this agent uses these MCPs, this system prompt, this memory backend".
- Memory portability. Modern agents have built in tools to have some kind of memory mechanism, where important pieces of past conversations are available as context. Should memory be decoupled from the harness, so that the owner (you) fully own the agent memory, or should it also be vendor locked? I have a non-tech friend who swears by ChatGPT and won't switch over to any other provider because ChatGPT already has all of their past conversation history. I can already see major providers holding memory as hostages to continue to incentivize vendor lock-in.
The Agent Protocol
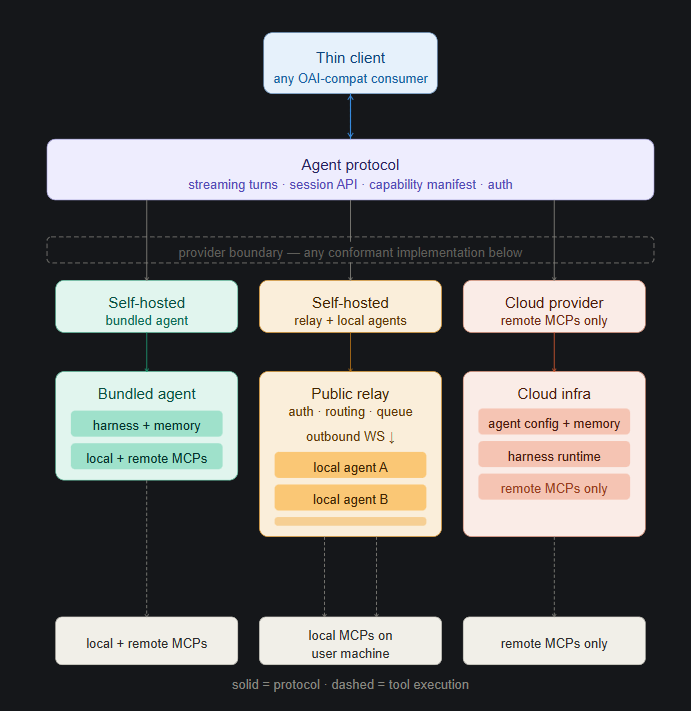
What I imagine is something like the above. There'd be a new standardized API schema referred to as the Agent protocol, similar to the current landscape of the "OpenAI compatible endpoint schema". Any thin client (ie: a browser extension, CLI, IDE plugin, or even direct OS level integration) would simply have to be configured to invoke a user-provided Agent-protocol compatible API.
The API would work similar to the different providers today:
- Commercial providers who offer a fully hosted package, and users are able to tune their agent behavior, integrate remote MCP servers, etc through the providers' own interfaces.
- A fully self-hosted provider, either hosted only with a local endpoint or behind a public domain that can be reached from public internet, where both the relay (the network layer) and underlying agent both run locally.
- A public relay (ie: something like Cloudflare/Tailscale reverse tunnels) that abstracts away the network layer, and the user only needs to configure their local agent to be exposed through the public relay.
APIs would be something like:
/agents-GET- Lists all agents and their capabilities
/agents/:agentid-GET- Gets detailed information for a given agent
/agents/:agentid/sessions-POST- Creates a new chat session with a given agent
/agents/:agentid/sessions-GET- Lists all prior chat sessions for a given agent
/agents/:agentid/sessions/:sessionid-POST- Resume existing session
- Sample request:
{
"message": "check my open github issues and summarise",
"stream": true
}- Sample response, through SSE streaming
// turn: model decides to call a tool
event: turn
data: {
"turn_index": 0,
"type": "tool_call",
"tool": "github.list_issues",
"input": { "state": "open", "assignee": "@me" }
}
// turn: tool result returned to model
event: turn
data: {
"turn_index": 1,
"type": "tool_result",
"tool": "github.list_issues",
"output": { "count": 4, "preview": "[...]" }
}
// delta: streaming final response tokens
event: delta
data: { "turn_index": 2, "type": "text", "delta": "You have 4 open" }
event: delta
data: { "turn_index": 2, "type": "text", "delta": " issues: ..." }
// done: signals completion with usage metadata
event: done
data: {
"session_id": "sess_01jx4k...",
"total_turns": 3,
"input_tokens": 812,
"output_tokens":204
}The API would continue to stream intermediary turn data that the frontend can decide to display the user.
The API won't need to store the full conversation client side and emit the entire history as context like current OpenAI-based stateless design.
// stateless OAI spec
{
"model": "gpt-4o",
"messages": [
{ "role": "user", "content": "what's the capital of france?" },
{ "role": "assistant", "content": "Paris." },
{ "role": "user", "content": "and germany?" }
]
}Instead, the client can assume that the agent is stateful, and can continue to keep POSTing to a given sessionId with the user's prompts and is able to return a continued output. For rendering purposes of displaying past chat messages for a given session (ie: user wants to resume an old chat session), it would be able to pull up the past chat history through a GET API call, purely for rendering purpose, maybe even we can add pagination to the API. But for any follow up prompts the client would simply be able to POST without actually needing to pass the full conversation history to the underlying agent in the Agent Protocol.
Authentication
There's one thing I haven't touched on yet that I think is actually the hardest part of making any of this work safely: authentication.
Invoking a personal agent isn't like calling the an OpenAI-compatible API. When you give someone an API key to your agent, you're not just giving them access to a chat interface. If your agent has filesystem MCP, browser MCP, local API access, you're essentially handing them shell access to your machine. The blast radius of a leaked API key here is categorically different from a leaked LLM provider key where the worst case is someone running up your bill.
At minimum I think the protocol needs to think about two separate concerns:
- Who is this invoker
- What are they allowed to do
OAuth 2.0 covers both cleanly, and it's already the standard for delegated access across the web. The invoking client requests a scoped token from the provider, the provider handles identity verification, and the token that gets issued is constrained to specific capabilities, kind of like scoped access to specific tools (which already is the paradigm for many existing agents). So a browser extension could get a token that only lets it invoke web_search, with no access to filesystem or browser. That's the kind of granularity you'd actually need before handing out access to a personal agent.
First time a new client tries to authenticate from a new IP address, new hardware fingerprint, etc, the provider should be able to issue a step-up challenge. Some kind of response saying that your request needs authentication. This can be something like your phone getting a push notification that you approve, which then the client gets a short-lived token with a refresh. This is exactly how banking apps and password managers handle new device enrollment, so the UX is already familiar. Whether that's TOTP, WebAuthn, or a hardware key like a Yubikey can be a provider implementation detail. What matters is that the protocol has a hook for it. Concretely that's just a 401 response with a challenge header that compliant clients know to handle, with the actual mechanism left to the provider.
I'd argue the scoping system is actually the most important piece though. It's what makes the protocol safe enough to build real clients on top of. Without it, any access is full access, and no reasonable person would expose their personal agent to third-party clients. With it, you can grant a trusted IDE plugin broad access and a random browser extension narrow access, and revoke either independently. One thing I'm not fully sure though is if the tool call scoping/gating should be fully handled within the agent level and not really exposed up on the protocol level, or if there should be some protocol level constructs that the agent will have to integrate with.
So... should I build this?
I think it would be meaningful if I become the pioneer of the agent protocol, but I don't have any big ambitions like that. For now, I'm going to figure out a way to bridge my local agent with my web browser, maybe open source it, and then we can see what happens next.