Vibe (spec-driven) coded App with 100% local AI

I've vibe coded apps at home using Intellij + Junie with a paid subscription. I wanted to challenge myself this time to do a much larger app purely using a local AI stack.
The tools I used during this project includes:
- Intellij
- primary IDE
- KiloCode plugin
- Agentic coding plugin, which is a fork of Cline
- spec-kit
- Spec-driven development toolkit
- LMStudio, later switched to vLLM
- Local OpenAI compatible LLM engine+server
- Qwen3.5 122B A10B Q4_K_M quant
- Model of choice
- Tavily MCP
- Web search capabilities, primary used to look up documentation
The end result is approximately 8500 LOC for the backend and 4000 LOC for the frontend, which can be seen in the following repo:
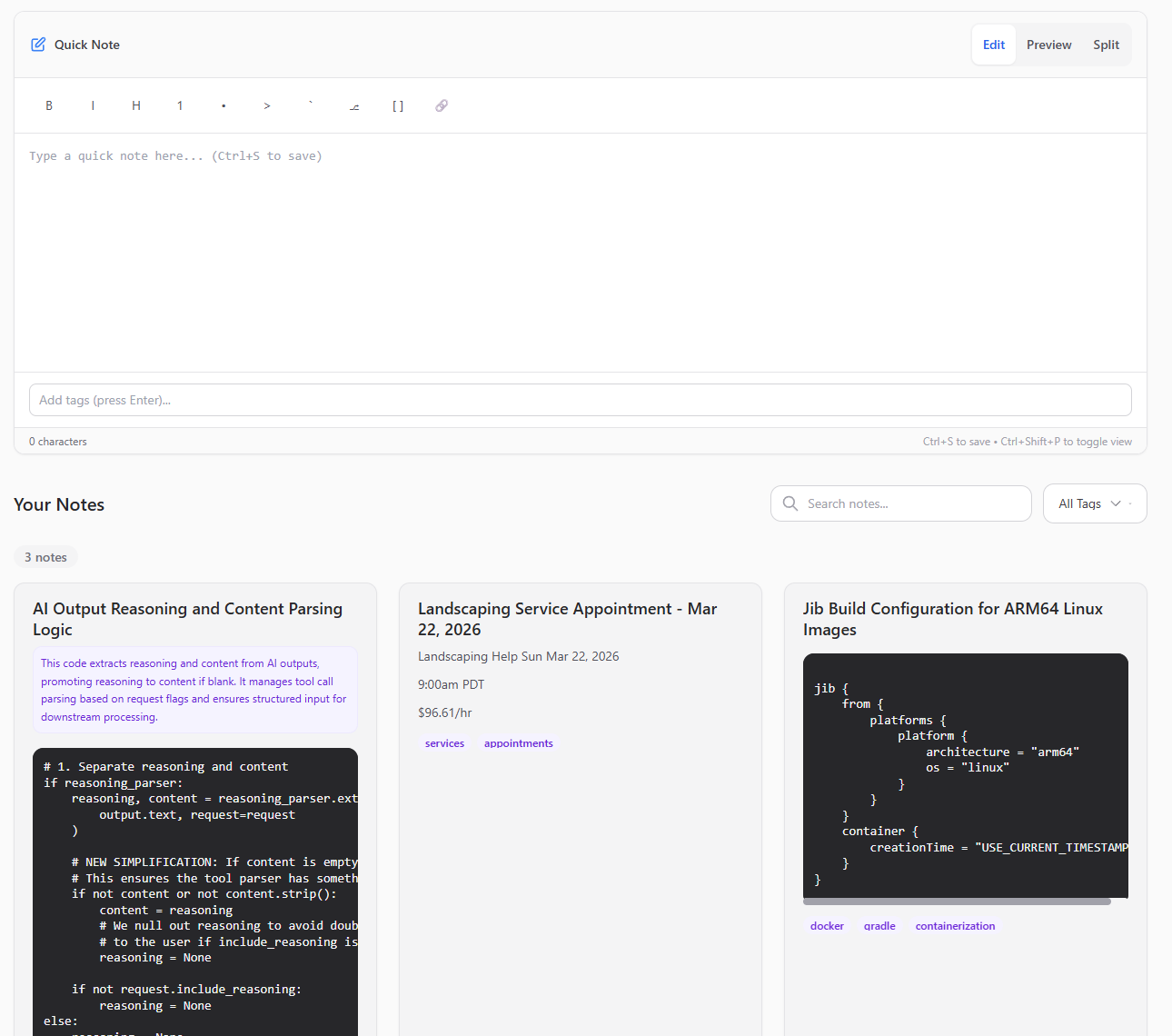
I decided to do a practical notes app that could be self-hosted, as the prior notes app that I was using had stability issues with the service randomly going down.
The scope is quite simple, requirements are clear, and I thought it was a good test for this endeavor.
Here are the key takeaways that I learned in this experiment:
- Use vLLM or SGLang to run the models. LM Studio will slow you down a LOT, due to constant prompt-processing loops. The one-time setup I had to do was frustrating, but it was well worth it. The way it speeds up prompt processing essentially increases productivity 2-3x. Sure, token generation doesn't get any faster. But just being able to remove the frustration of having to wait upwards to a minute on processing large uncached prompts, which is incredibly common in agentic workflows, really tanked productivity, and switching to vLLM was the right call.
- After switching to vLLM though, I was getting more frequent tool call failures, which became super annoying. What would happen is that the tool call would happen inside the thinking block:
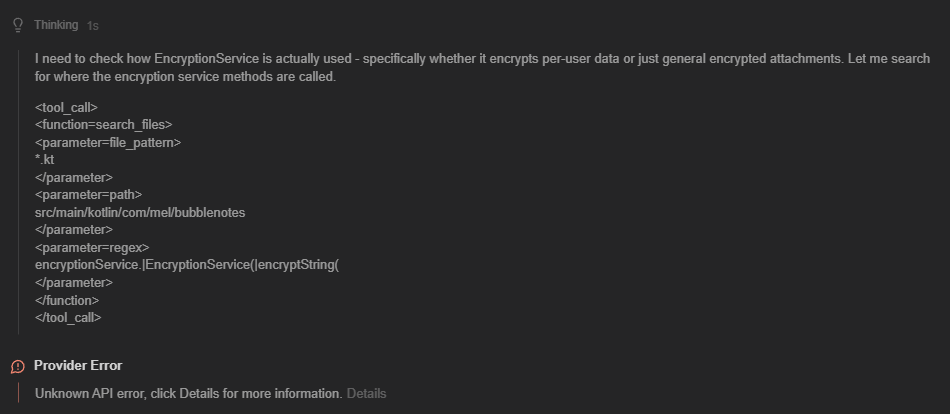
For some reason, this was much more frequent in vLLM than LM Studio, which then I found this open bug report for LM Studio:
https://github.com/lmstudio-ai/lmstudio-bug-tracker/issues/1592
Tool call parser scans inside <think> blocks, creating false-positive parse attempts from reasoning content #1592
Essentially, a bug in LM studio was actually "improving" my experience due to a known bug where it would parse tool calls even if they were part of the reasoning block.
I decided to apply the same "hack" in vLLM by making an update to where the tool parsers are invoked:
The "fix" that I did was quite simple - if the parsed content was empty but the reasoning wasn't, I'd use the reasoning blob as the content instead, which would be used as both the agent output and fed into the tool parser.
# 1. Separate reasoning and content
if reasoning_parser:
reasoning, content = reasoning_parser.extract_reasoning(
output.text, request=request
)
# NEW SIMPLIFICATION: If content is empty/blank, promote reasoning to content
# This ensures the tool parser has something to look at.
if not content or not content.strip():
content = reasoning
# We null out reasoning to avoid double-displaying the same text
# to the user if include_reasoning is True.
reasoning = None
if not request.include_reasoning:
reasoning = None
else:
reasoning = None
content = output.text
# 2. Proceed with standard parsing (no changes needed here)
auto_tools_called = False
tool_calls, content = self._parse_tool_calls_from_content(
request=request,
tokenizer=tokenizer,
content=content,
enable_auto_tools=self.enable_auto_tools,
tool_parser_cls=self.tool_parser,
)This approach essentially got rid of all of the tool call failures, making the experience much more seamless.
- Utilize full 256k context size available on this model. System prompts will quickly fill up 50-60k, and reading each code file can take anywhere between 5-10k per file. I configured KiloCode to perform context compression at 80%, to keep the context size at a size where the LLM is still "smart" (output degrades as more context is used).
- KiloCode + spec-kit is the most mature agentic coding plugins available for Intellij. Sure, Junie is still great, but it is very context heavy, doesn't support local models, and updates are very infrequent compared to the speed of innovation in the agentic coding side of things. I've also tried Devoxxgenie, but it's not mature yet to be the main daily-driver. There are no retry mechanisms when there are tool call failures, meaning that it just ends up stopping processing the task/prompt, and requires 24/7 cognitive attention from the human operator to re-drive failures. The way it manages context is not great for long-running tasks that require smart memory management, whereas KiloCode utilizes the LLM to compress the context to smaller amount of tokens, which is better at memory retention.
- I've tried gpt-oss-120b and nemotron-3-super, but gpt-oss-120b fails tool calls a little too frequently, with no application level hacks to work around, and nemotron-3-super is not great at debugging - it almost always falls into huge reasoning loops and is unable to make significant progress.
- The model is obviously not perfect - when faced with more challenging debugging problems, even Qwen3.5-122b will generate tens of thousands of reasoning tokens, often repeating itself over and over again nonstop, which I had to explicitly set max token output to around 2000 so that these "bad" output won't poison the context.
What's next?
This exercise gave me a lot of first-hand insight on the capability of local models, specifically Qwen3.5-122b. Compared to the closed Anthropic models I have access to at work, there's definitely some intelligence gap. But Qwen3.5 is the first model that I have been able to use that actually felt like it has the capability to compete with closed models for "real" engineering.
Once I have access to some more VRAM (I already ordered Mellanox connectx-6 cards for 100Gb networking between my two servers) I really want to try MiniMax M2.5, which seems to be the ceiling of what my servers are able to run for the near future. Now time to save up for a second RTX Pro 6000....